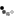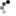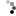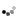کدهای مدیریت نشده (Unmanaged Code) :
کد های مدیریت نشده یا در واقع کدهای محلی (Native Code) ،در نتیجه کامپایل سورس برنامه ها به دستورات قابل فهم برای سیستم عامل و پردازنده های خاص به وجود می آید ؛یعنی کدمحلی تولید شده در سیستم عامل Windows شرکت مایکروسافت با کد محلی تولید شده برا سیستم عامل لینوکس یکی نیست ! .
این نوع کد مزایا و معایب خاص خود را دارد ؛ برای مثال سریع اجرا می شوند ولی قابل حمل نیستند. که سریع بودن یک مزیت و قابل حمل نبودن یک عیب است ،البته با Compile مجدد سورس برنامه در ماشین مورد نظر می توان از برنامه استفاده کرد .
شکل زیر روند تولید برنامه ها در حالت کد محلی را نماش می دهد ؛که در اولین مرحله سورس کدهای قابل درک برای انسان پس از مرحله ترجمه (کامپایل) به دستورات قابل فهم برای پردازنده ها و سیستم عامل ها تبدیل می شوند.
زبان های مثل : Delphi,C,C++ چنین خروجی را تولید میکنند.
برای مثال این قطعه که به زبان دلفی نوشته شده را در نظر بگیرید :
var
A, B, C: Byte;
begin
A := 1;
B := 2;
C := A + B;;
end
بعد از کامپایل به چنین کدی تبدیل می شود :
;A:=1;
mov byte ptr [ebp-$05],$01
;B:=2;
mov byte ptr [ebp-$06],$02
;C:=A+B;
mov al,[ebp-$05]
add al,[ebp-$06]
mov [ebp-$07],al
و در آخر کد محلی ای که تولید می کند چنین چیزی است که اصلاحاً Opcode نامیده می شود و معادل زبان ماشین دستورات Assembly است، که این Opcode ها بسته به معماری پردازنده می توانند متفاوت نیز باشند.
//A:=1;
C645FB01
// B:=2;
C645FA02
// C:=A+B;
8A45FB
0245FA
8845F9
مثلا در اینجا (معماری IA32) ، آپ کد 88 مربوط به mov می باشد ولی ممکن در معماری های دیگر پردازنده ها این مقدار فرق داشته باشد.حالا این رشته(C645FB01C645FA028A45FB0245FA8845F9) معادل همان کد دلفی است ! (فعلا برای پیچیده نشدن، قسمت مربوط به تعریف متغییر ها و … را لیست نکردم و این کد مربوط به قسمت جمع کردن مقادیر دو متغییر A و B و قرارد دادن نتیجه در C است).
کدهای مدیریت شده (Managed Code) :
کد های مدیریت شده تفاوت های زیادی با کدهای مدیریت نشده داردند هم از نظر روند کامپایل و هم اجرا.
برخلاف برنامه هایی Native Code که فقط یک بار به زبان ماشین (Opcode) ترجمه می شوند این برنامه ها برای اجرا در هر سیستم در اولین اجرا بعد از چند بار ترجمه به زبان ماشین ترجمه می شود. به همین دلیل شما می توانید یک کد را یکبار به فایل اجرایی (Assembly) تبدیل کرده و این فایل اجرایی شماست که خودش را سازگار با معماری های مختلف پردازنده ها یا سیستم های عامل کامپایل میکند و Opcode های سازگار با آنها را تولید میکند (در ادامه دقیق تر توضیح داده شده) به همین دلیل این برنامه ها از نظر قابل حمل بودن بسیار انعطاف پذیر هستند.
مراحل ایجاد و اجرای برنامه ها :
سورس کدهای نوشته به زبان های نظیر C# در قالب یک فایل Dll یا exe که یک Net Assembly. نیز نامیده می شود به یک زبان میانی (CIL یا MSIL) تر جمه (کامپایل) می شود. و این فایل ها به عنوان فایل اجرایی دراختیار کاربران قرار می گیرد. به این نکته نیز توجه کنید که فایل های َAssembly تولید شده بدون وجود Net Framework. در سیستم مقصد به هیچ وجه قابل اجرا نخواهند بود ،این هم یکی از معایب ! .
در مر حله بعد ؛پس از اینکه کاربر فایل اجرایی را اجرا می کند ترجمه نهایی صورت می گیرد؛ توسط بخشی از CLR به نام JIT کد ها از زبان میانی به کدهای محلی قابل اجرا در سیستم مقصد ترجمه می شوند.
برای درک بهتر به تصویر زیر توجه کنید.
این توضیحات در موردNET. بود ،ولی زبانی مثل Java نیز عملکردی مشابه دارد در NET. ما Assembly ها رو داریم و در جاوا Byte Code ها رو و … !
حال این که ما کدام را انتخاب کنیم ،به نوع پروژه هایمان بستگی دارد Unmanaged Code برای برنامه های سیستمی بیشتر توصیه می شود چرا که در Managed Code ما از نظر دسترسی به برخی منابع بسیار محدود هستیم برای نمونه :به هیچ وجه امکان استفاده از مجموع دستورات پردازنده (SSE) وجود ندارد ،امکان دسترسی به Pipeline گارت گرافیک و هسته آن (GPU) وجود ندارد .که این مورد دوم در برنامه های چندرسانه ای و بازی ها بسیار مهم است. البته در زبانی مثل #C ما برای دسترسی مستقیم (البته نه به معنای واقعی !) به حافظه می توانیم مستقیماً از Windows API مربوط به این کار استفاده کنیم، یا با استفاده از یکی از ویژگی های ذاتی #C یعنی اشاره گرها (Pointer) مانند++C این کار را انجام دهیم (این ویژگی هابه صورت پیشفرض غیر فعال هستند.).